Distributed Computing with Spark SQL
This course is all about big data. It’s for students with SQL experience that want to take the next step on their data journey by learning distributed computing using Apache Spark. Students will gain a thorough understanding of this open-source standard for working with large datasets. Students will gain an understanding of the fundamentals of data analysis using SQL on Spark, setting the foundation for how to combine data with advanced analytics at scale and in production environments.
Buy Now AED 170.99 + VAT
Monthly Subscription Starting at AED 99 + VAT
- Level Professional
- المدة 14 ساعات hours
- الطبع بواسطة University of California, Davis
-
Offered by

عن
This course is all about big data. It's for students with SQL experience that want to take the next step on their data journey by learning distributed computing using Apache Spark. Students will gain a thorough understanding of this open-source standard for working with large datasets. Students will gain an understanding of the fundamentals of data analysis using SQL on Spark, setting the foundation for how to combine data with advanced analytics at scale and in production environments. The four modules build on one another and by the end of the course you will understand: the Spark architecture, queries within Spark, common ways to optimize Spark SQL, and how to build reliable data pipelines. The first module introduces Spark and the Databricks environment including how Spark distributes computation and Spark SQL. Module 2 covers the core concepts of Spark such as storage vs. compute, caching, partitions, and troubleshooting performance issues via the Spark UI. It also covers new features in Apache Spark 3.x such as Adaptive Query Execution. The third module focuses on Engineering Data Pipelines including connecting to databases, schemas and data types, file formats, and writing reliable data. The final module covers data lakes, data warehouses, and lakehouses. Students build production grade data pipelines by combining Spark with the open-source project Delta Lake. By the end of this course, students will hone their SQL and distributed computing skills to become more adept at advanced analysis and to set the stage for transitioning to more advanced analytics as Data Scientists.الوحدات
Getting Started
-
 1
Videos
1
Videos
-
 1
Readings
1
Readings
-
 1
Discussion
1
Discussion
![]() 1
Discussions
1
Discussions
- Learning Goals
![]() 1
Videos
1
Videos
- Course Introduction
![]() 1
Readings
1
Readings
- A Note From UC Davis
Introduction to Spark
-
5
Videos
-
2
Readings
![]() 5
Videos
5
Videos
- Why Distributed Computing?
- Spark DataFrames
- The Databricks Environment
- SQL in Notebooks
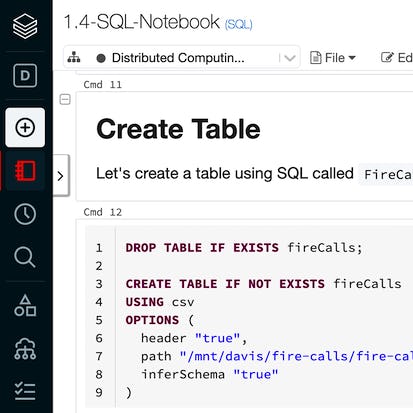
- Import Data
![]() 2
Readings
2
Readings
- Course Lectures
- Readings and Resources
Review
-
 1
Assignment
1
Assignment
![]() 1
Assignment
1
Assignment
- Module 1 Quiz
Spark Core Concepts
-
6
Videos
-
1
Readings
![]() 6
Videos
6
Videos
- Module Introduction
- Spark Terminology
- Caching
- Shuffle Partitions
- Spark UI
- Adaptive Query Execution (AQE)
![]() 1
Readings
1
Readings
- Readings
Review
-
1
Assignment
![]() 1
Assignment
1
Assignment
- Module 2 Quiz
Engineering Data Pipelines
-
7
Videos
-
1
Readings
![]() 7
Videos
7
Videos
- Module Introduction
- Spark as a Connector
- Accessing Data
- File Formats
- JSON, Schemas and Types
- Writing Data
- Tables and Views
![]() 1
Readings
1
Readings
- Readings
Review
-
1
Assignment
![]() 1
Assignment
1
Assignment
- Module 3 Quiz
Data Lakes, Warehouses and Lakehouses
-
7
Videos
-
1
Readings
![]() 7
Videos
7
Videos
- Module Introduction
- Data Lakes vs. Data Warehouses
- What is a Lakehouse?
- Delta Lake
- Delta Lake (Demo)
- Delta Advanced Features (Demo)
- Continuing with Spark and Data Science
![]() 1
Readings
1
Readings
- Readings
Review
-
1
Assignment
![]() 1
Assignment
1
Assignment
- Module 4 Quiz
Course Summary
-
1
Videos
-
1
Discussion
![]() 1
Discussions
1
Discussions
- Self-Reflection
![]() 1
Videos
1
Videos
- Course Summary
Auto Summary
Unlock the power of big data with the "Distributed Computing with Spark SQL" course, designed specifically for those with SQL experience aiming to advance their skills in data science and AI. This professional-level course, offered by Coursera, dives deep into the world of distributed computing using Apache Spark, an essential tool for handling large datasets. Guided by industry experts, you'll explore four progressive modules that cover everything from the basics of Spark architecture and SQL queries to optimizing Spark SQL and building robust data pipelines. You'll start by familiarizing yourself with the Spark and Databricks environment, then move on to essential Spark concepts such as storage, compute, caching, and performance troubleshooting. You'll also learn about the latest features in Apache Spark 3.x, including Adaptive Query Execution. The course will equip you with the knowledge to engineer data pipelines efficiently, covering topics like database connections, schemas, data types, and file formats. Finally, you'll delve into advanced concepts like data lakes, data warehouses, and lakehouses. Over 840 minutes of comprehensive content ensures you develop a solid foundation in Spark SQL, enabling you to perform advanced data analyses and prepare for more sophisticated analytics roles. Flexible subscription options are available, including Starter, Professional, and Paid plans, making it accessible for various learning needs. Ideal for aspiring data scientists and professionals seeking to enhance their SQL and big data capabilities, this course is your gateway to mastering distributed computing with Apache Spark. Join now and elevate your data journey to new heights.

Brooke Wenig

Conor Murphy